This project was inspired by a smaller Sketcher application developed by Zaid Alyafeai.
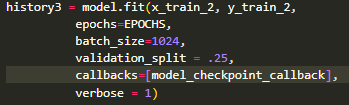
There are two models present on this page. Both were trained on the full 345 class dataset from Google.
The link to an earlier, simpler* Colaboratory Notebook prototype with only 160 classes
is available here: Colab
*This smaller prototype was trained using Google's Tensor Processing Unit
(TPU)
The architecture of training is defined by the following Convolutional Neural Network
structure:
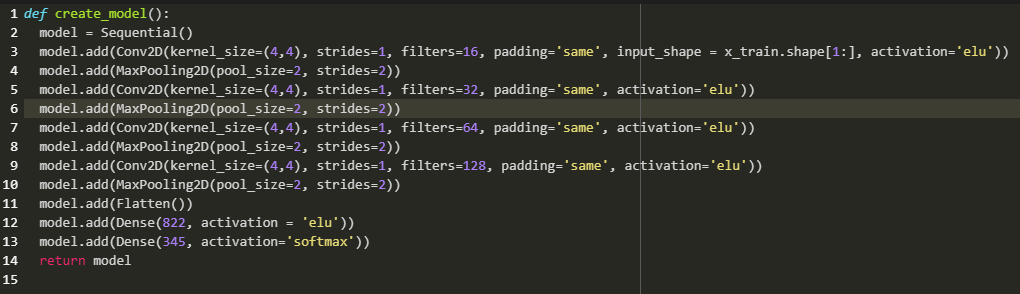
The specific architecture was arrived at through 50 rounds of optimization, performed by
scikit-optimize, selecting from the following parameters:
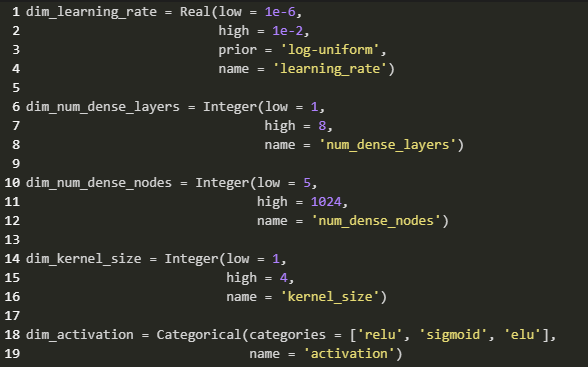
The optimization was run on a subset of the full dataset, specifically only 60,000 training
and 5,000 validation sets.
Here is the convergence plot of the optimization:
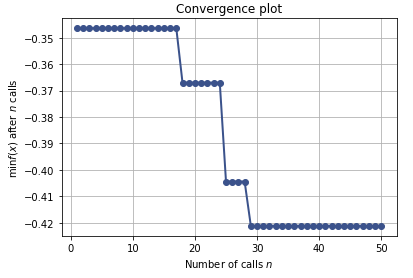
The full dataset contained 1,656,000 sets, with an 80/20 train/validation ratio.
Below are two charts, showing the accuracy and loss, respectively, over the training
epochs:
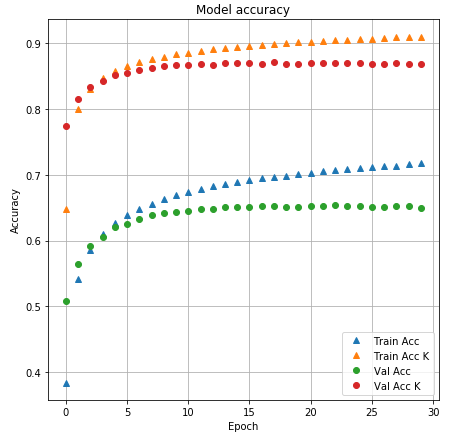

Minor overfitting is present after roughly the 18th epoch.